
This month begins my exploration of a PhD Studentship which aims to explore an investigate the concept of ‘disjunctive realms’. Digital and Physical space’s relation comprise the most significant example of this disconnect. This is the focus of my research. Below is my initial proposal for the PhD, which outlines key themes I aim to tackle.




My initial investigations will take place around the exploration of non-Euclidean spaces. I find that these are the most intriguing and visually comprehendible examples of physics being subverted in digital environments, to the vast majority of people. Therefore they provide a fantastic metaphor for non-digitally minded people to be able to understand how we can further enhance digital spaces beyond the normal limits of their regularly inhabited physical space.
I have included some key examples of digital experiences where spaces are enhanced and manipulated beyond Euclidean simulations. (The reality we exist within is in fact non-Euclidean itself, however using Euclidean geometry, we can accurately simulate it. Therefore spaces which cannot be simulated within this are referred to as non-Euclidean).
Superliminal is an example which uses a technique coined as ‘forced perspective’. Within the game code, objects are maintained at the same size, once held by the player in the viewport. So as they move further from the user, they must increase in size due to the nature of perspective, and as they come closer, they are reduced in the same way. This very simple notion, is both visually incredible and provides many puzzling experiences, both mentally and visually for the players.
Miegakure and 4D Toys are both made by the same game designer, with the latter being both a fundraiser and taster for the main experience of a 4-Dimensional Puzzle game. The explanation of a 4D viewing experience in the video above is really provoking, and with the game still not release, these videos provide our only current glimpses into this 4D coded experience. Our inability to comprehend the dimensional of time in a physical plane makes this non-Euclidean game that much more interesting.
Portal is a classic examples of spatial bending game experiences. With the user having access to a portal gun, enabling them to create 2 connected portals in the game environments to traverse spaces which would otherwise be impassable. With a simple teleportation and camera viewport set of tricks, the experience feels realistic and fluid, allowing a entirely unique game experience to take place.

Starting to think about my own creative insights into this ‘non-Euclidean’ environment, I usually begin by making seemingly very abstract and unrelated visual outputs. These tend to range greatly, from very tactical objects, to animation and to interactive digital experiences. As with the proposal of my PhD, I enjoy spanning across digital and physical spaces, to explore the benefits and intrigue both environments can supply to both the creator and users of these objects/experiences.
This first design, is taking from the De Stijl movement, in order to simplify and abstract the experience of using a keyboard. I wanted to represent the experience of an alien or someone in the past encountering a keyboard, and how that might feel to them as foreign object. But at the same time, I aimed to design something which I could potentially use to generate interactive digital experiences. I haven’t yet created any coded experience with this object, but following through with these experiments, I may find use in it, or create a similar alternative device to interact with coded tests.
After thinking about the usage an alternative keyboard could supply, I began thinking about memory fragments, which is something digital exploration brings to me. Having just finished building a new computer from scratch, I wanted to push the boundaries of this device, to see what level of visuals I could achieve. I was thinking of the ways in which gravity and physics applies in literal space, and how I can plan upon this phenomenon in simple animations. Water as a liquid, heavily obeys these rules, and so using invisible barriers, its properties can be manipulated in digital environments. I took some old 3D scans as memories, and began to create these ‘purging’ animations involving water as seen again in the next few animated experiments.

Continuing with these existing 3D models I had created, I started to think about how I could expand the ideas of purging and remembering in digital space through its properties unavailable in physical space. Crazy horse, a native American response to the controversial Mount Rushmore was a monument I had visited over 10 years ago as a small child. I wanted to learn how to take photogrammetry from large scale 3D objects in the real world, and began exploring into a method to syphon off 3D data, intercepting it before it reaches your computer’s graphics card. This enabled me to take models from google maps, or any other free resource, and convert them into objects which I could print, animate, or place into game engines. This experiment was really interesting as a base concept, and as often with my work, I create many loose ends in my miniature pieces, that I later subliminally tie together into a larger concept.
The photogrammetry system of extracting data then got me thinking about how else I could reuse my knowledge of photogrammetry (a practice of taking many photos, which can then be computed into 3D models using a range of software). I attempted to digitise myself for the first time, which came out incredibly clean to my surprise due to the high fidelity required to provide a convincing replication of the human form. Although computers are easily tricked into recognising humans, we often put things not quite human into the uncanny valley, which makes them odd or weird in our minds, dehumanising them.
I realised after creating the photogrammetry version of myself, not only could I 3D print this for my own amusement (which I immediately did), but I could also attempt to create a game character by rigging it with a skeletal structure. I did this through the use of a free adobe software called Miximo, after heavily cleaning up and retexturing the model to make it’s quality much higher. After processing the model through Mixamo, I had to convert and adapt it to function with base animations within the unreal 4 engine, which is a standard program used in the games industry (along with unity).
After successfully creating myself as a character within the engine, I wanted to make a form of demo to allow people to play with this character, and also perhaps experience some of my past work, as a form of closing point between what I aimed to uncover in my undergraduate study, and what I may pursue now. Although these won’t be entirely separate explorations, I wanted a space which formed a memory capsule to that which I had created until this point. I began exploring the shatter effect, which I done once years ago for a small project, but working with much higher fidelity models, and more impactful visuals. Once I had got this up and running, with a simulated form of raytracing (which was incredibly finickity on my particular graphics card), I scaled up the entire process to a whole series of objects as seen below.
Here you can see this final demo with standard game controls, alongside three additional functions I implemented (R = Restart Function, T = Time Slowed, F = Fast Forward). It is a form of gallery or science exhibition in a unknown space. As with normal spatial conventions, look but do not touch! However the user will quickly find out what happens if they break those rules, as everyone who has invested time in a games or digital space will know, conventions are made to be broken, and always proves more intriguing than following along with the instructions.
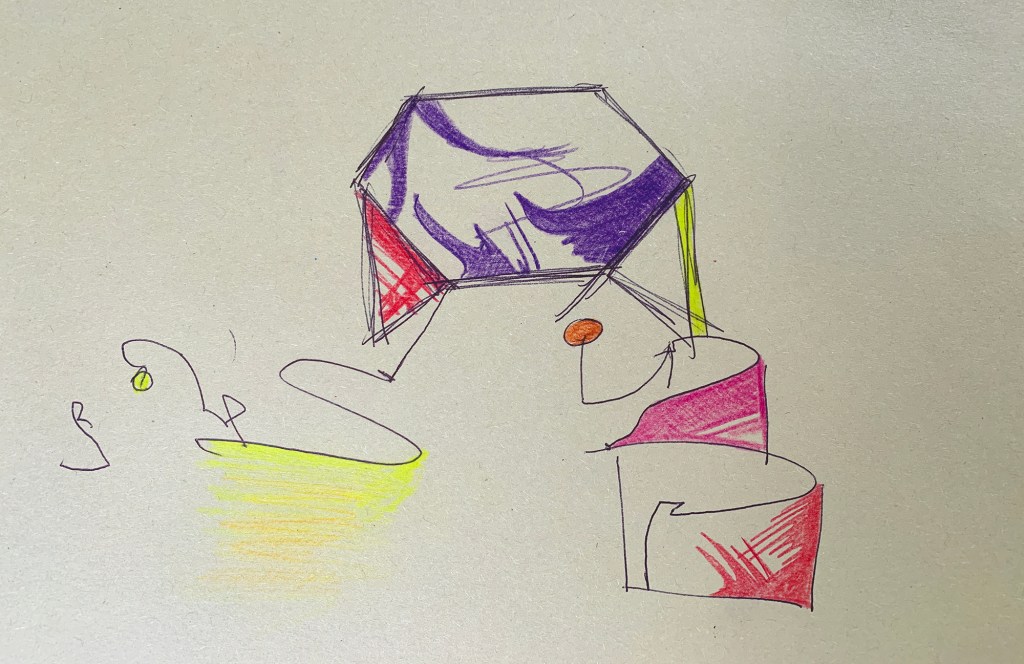
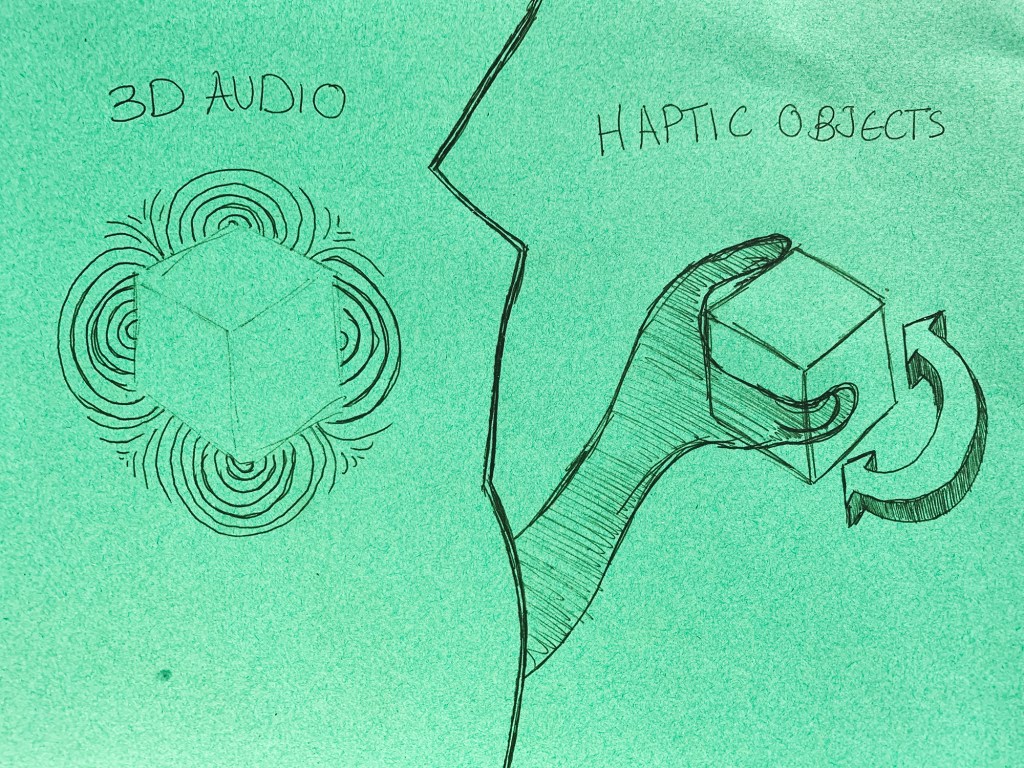
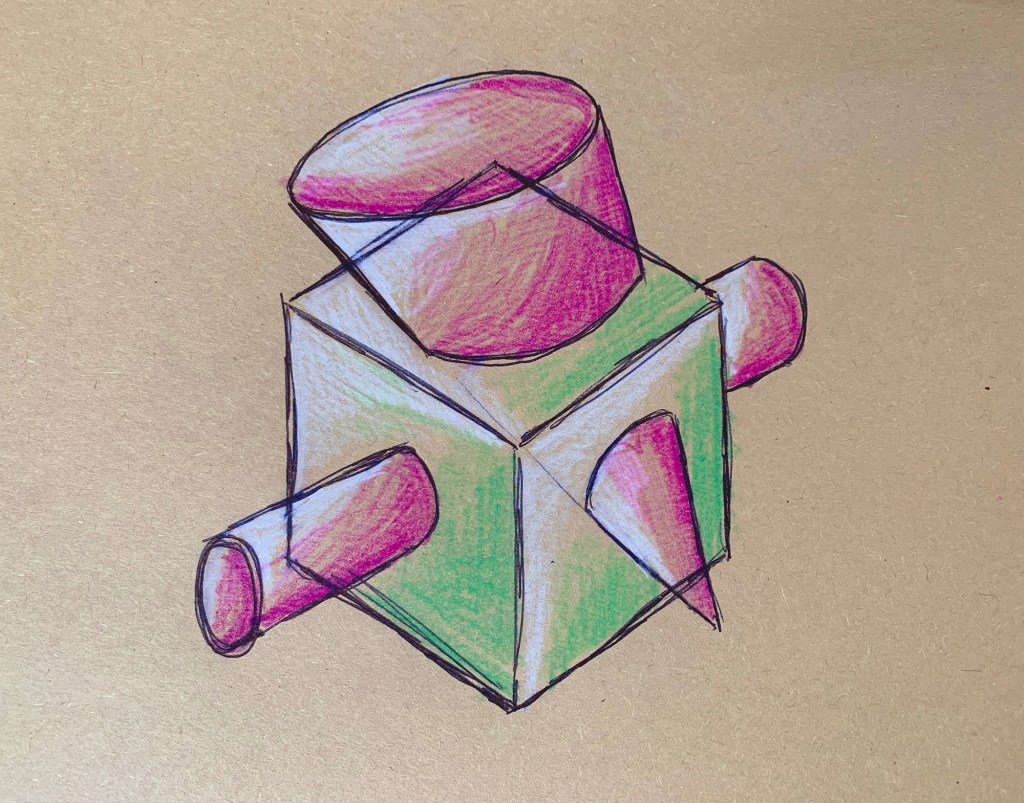
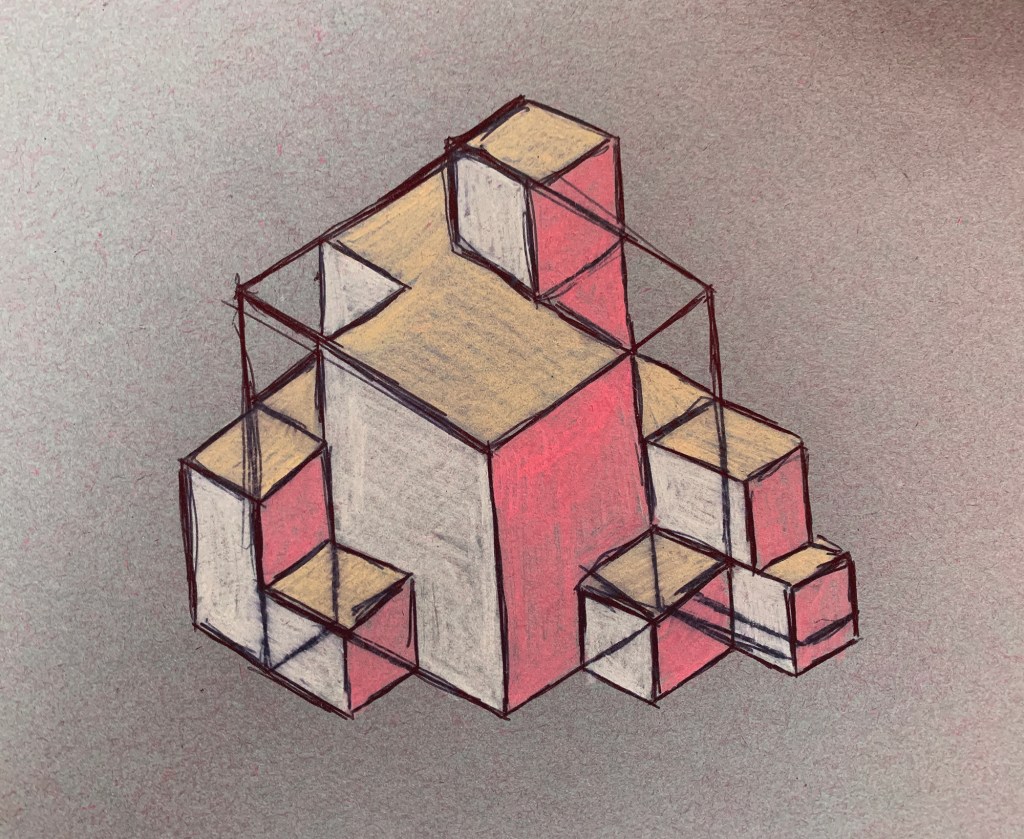

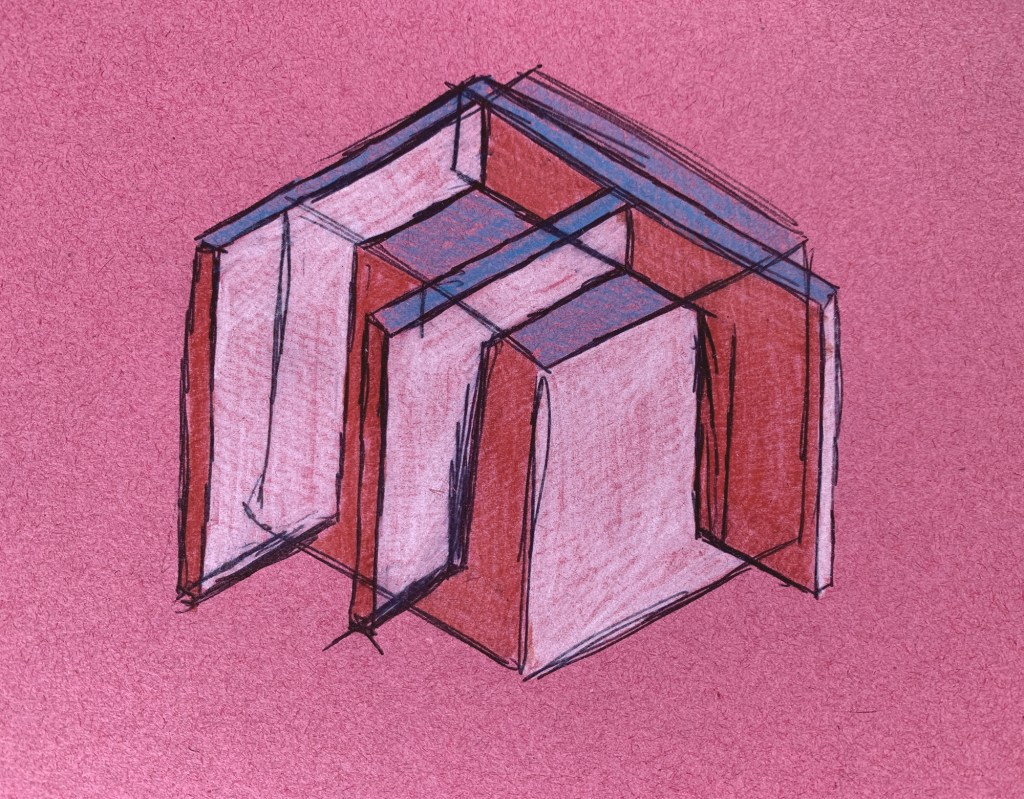
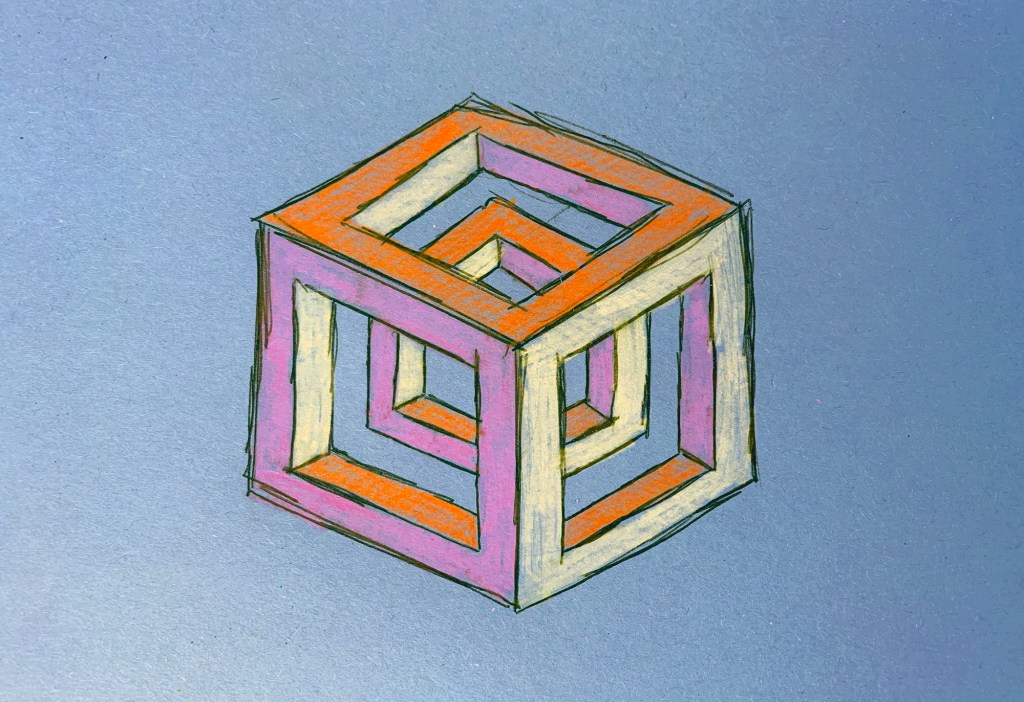
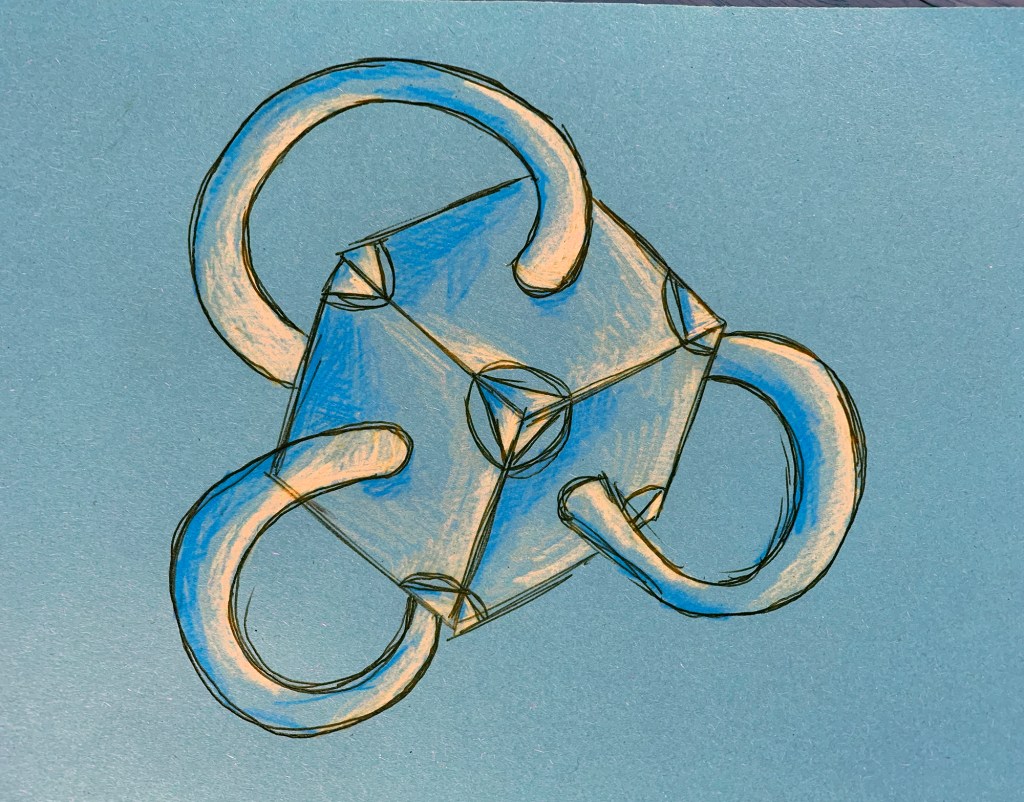
Looking at a call for papers from the multimedia anthropology lab at UCL, which resonated heavily with many of the ideas I have currently been having, I decided to draw some quick sketches up in order try and grab a bit of visible clarity on the subject. I often do this as a way to formulate abstract ideas inside my mind. This process in itself, of generating ideas fits heavily within their explorative area. By attempting to find alternative methods of exploration and learning through alternative experiences and encounters with alterity. Drawing these cubes out was a way of envisaging a tesseract. Spatially representing a fourth physical dimension is incredibly problematic, and touched upon in the 4D toybox I mentioned earlier.
However I want to explore my own methods of using forced perspective, alongside shifting interactive interfaces which could potentially enable some form of realised four dimensional metaphors as interactive puzzle, or simple game experiments.
This animation above is something a little more concrete which aims to explore this tesseract like visual. OogBrain seems like a whimsical name, but it has foundations in many aspects of the human condition which I am using. It provides a sense of anonymity online, while in many ways providing a memorable identity in the opposite sense. But I enjoy the secondary artistic identity it enables me to possess.
In the animation, orthographic perspective is used in order to make objects appear the same size irrespective of their distance from the camera which is very unusual in a physical space. It enables a particular angle to provide us with a clear set of characters, while every other angle appears distorted. This works in a similar form to an Escherian Stairwell, along with many other impossible shapes.

I have been fascinated with this concept of both forced perspective, and four dimensional physical space and tesseracts for a very long time as can be seen in this piece created in 2016. However I would like to increase the quality of the visuals of these ideas, and rather than having intricate and potentially confusing visuals which could overburden the concepts, I want to try and implement interactive elements into the same concepts to allow users to engage heavily.
Here I have tested out this concept of trying to experiment with creating a tesseract like visual. Since I know this is perfectly possible with highly complex shapes, I want to try and replicate the same method with 3D modelled versions of the cube drawings I did to find out if the result is an intriguing with them.
I exported both a smoothed a flat shaded version of the short animation. This is done through a process known as shrink wrapping within blender which seems very suiting. I feel that although the flat shaded angular version is more accurate to the digital environment it resides within, because I am aiming to represent this four dimensional space in the most pure form possible, in a simple visual, the flat sided triangle vertices of the second render draws away from the concept itself. The smoother version feels more of a natural process to watch.
Looking at this video which analyses a NVidia video synthesis technique, I am starting to think about how I may be able to use machine learning, in order to synthesise the environments which I am creating into something which feels a lot more otherworldly. I enjoy the concept of alterity or otherness which these sorts of experiences provide. I think this is obviously demonstrated by my creation of uncanny objects and spaces using simplified machine learning processes in the past. I need to aim to download Linux, most likely with Ubuntu as the main system in order to further experiment with machine learning, and potentially be able to begin editing and adapting the code myself.
I believe the video game environment I previously created could provide the perfect input for this machine learning experiment as not only are the colours already bright and vibrant, but they can be tweaked in order to work within a model like the one shown above. I think the environment itself is already odd enough, but by introducing this video synthesis layer on top, its entire visual could be twisted into another realm of digital space which I would enjoy to see materialised onscreen.












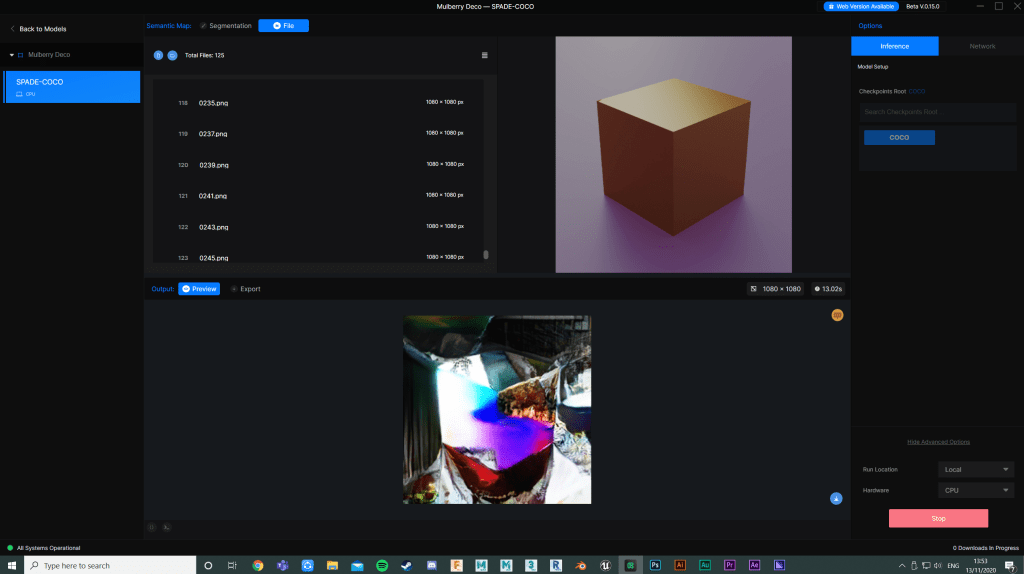
Putting several of the pieces I made before through a SPADE object synthesis machine learning algorithm resulted in some rather interesting generated imagery. I wanted to attempt to create short video pieces from a couple of these to further explore this, which involved manually outputting these animations as stills, and feeding those into ML software in order to generate another series of images which could be reconverted into video.
Unlike previous image flow attempts, each still would be processed separately from a different source image, but with the same semantic map detection. This is usually intended to be fed block colour semantic simple colour drawings, so it would be interesting to see how more complex yet vibrant imagery would confuse this process.
These were the two input videos I wanted to test. The first with very vibrant colours, and the second with more of a confusing visual for the computer to understand. This would take a long time to process long clips, and due to the way ML is processed, would significantly reduce the quality of even these short clips. So it would be worth testing to see if this process was viable at all.
The first output of the game engine shatter experiment I made earlier came out incredibly distorted. I enjoy the visual, but much of the striking imagery and ideas is incredibly abstracted beyond understanding. I wanted to try object synthesis in these images to see if the already uncanny objects could be perhaps more twisted but I think the combination of chaos and low quality make this example largely uninteresting.
The second example suffers from the same issues, but to a lesser extent. While the main visual is still somewhat recognisable, because it is already intended to be an uncanny object morphing in a tesseract style, it becomes far to abstract to provoke any kind of interesting thoughts from the viewer.


Starting to look at a anthropology conference from ucl mal, with the aim to submit something relevant to them by their deadline on December 2nd, I began to make these notes and insights from their brief. I starting by trying to make something basic in code which would express this intent to question the idea of being digitally indigenous. I think people often associate the term indigenous with a variety of physical places around the world, but it is something which often isn’t thought of in regard to facets of digital space.
Here I have made a quick run-through of the process of making this quick digital experiment. I enjoy the movement it invokes onto the user, forcing them a little out of the screen, rather than purely being teleported into the screen space, while also questioning the usually static way we interact with a monitor. It feels quite off to move your head in order to interact with a screen, and although eye tracking has become relatively widespread as an interactive method, this still complies with normative use of monitors.








Thinking about the ideas of this conference. I really believe that this work which I produced back in February which I never got to fully realise. I want to take a couple of parts of this and attempt to weave them together into more of a narrative.
Looking at this narrative of machine learning, and how I can begin to explain how it is used to convey both concepts of indigenous existence within digital space through its understanding of my selfie images and, as a visual representation of machine learning of data, I am beginning to test out different forms of animation. This first one uses a deformation map to alter the elevation of the surface on a sphere within animation software. I like the abstract nature it has possessed, but I think that the visual is too intangible to really clarify or enlighten anyone viewing it about machine learning, or how its understanding of vanity and materialism are transferred and abused within digital space.
I think this second visual uses similar methods, but creates a much meaningful visual. Starting off close up, we see abstract waves with odd plastic like textures. As this pans out, it becomes clearer that these form a warped face. This face is trained on cropped selfie images of my face. I think to pan out from this further could be extremely interesting as a potential for more research, and to create some kind of array of scale within machine learning, but I want to explore alternate experiments before I try to refine just one.
This next idea came from the way in which these machine learning visuals are trained. I have used the original images as a deformation map on a half dome around the sphere, and then applied the final texture as both visual and deformation to the sphere in the middle. This creates a very otherworldly aesthetic where its almost unclear which is effecting the other. It also looks rather off-putting due to the very jolting movement the water has, compared to the flowing visual of the orb. It creates a metaphor for the way machine learning reflects reality, and also for how it calms and blends together what it sees, only showing clearly, the things which are consistent across all the input material. I think doing a more zoomed in version of this visual, perhaps with some depth of field would make this idea more understandable, by making the contrast between flowing and jarring visual starker, and making the world appear even more uncanny in its fake reality.
Having rendered out this much closer up version, I feel that the contrast between the understanding of the machine, and the original images has become much more obvious. I really enjoy the otherworldliness that this animation has. It feels uncanny, which references towards the notion of a machine generated space. I wanted the environment to feel like it was digitally corrupted, not necessarily meaning this as a negative trait, but as a space or idea which was learned and perceived from physical reality. This reflective idea, of the egg or ball evolving because of its physical surroundings has become more visualised and real after making this animation. I also enjoy the gross nature that the ball possesses.
It feels to alive, as the machine runs through its simulated understanding, it shifts and changes and it begins to further understand my face. I want to explore more, the scale at which these machine algorithms can synthesise these images, and how we might go about looking for patterns in the magnitude of this data.
These two videos are each of 1000 generated images from 2 machine learning trained GANs I created. They use the same set of images, one cropped down just to my face only, and the other given the raw images. I really enjoy noticing what the computer continually picked up on. On a personal level, I weirdly feel some forms of memories from the uncropped ones while the ones which purely look my face lack this. The backgrounds sometimes oddly form into places which I remember if a large quantity of photos were taken in a particular colour pallet.
I think because of these memories which the computer is reconstituting for me, I want to further explore the uncropped versions more. They seem to have an oddly nostalgic effect, on quite a personal level, and think attempting to convey this scale of memory, and potentially the capacity for the computer to almost simulate memory in itself would be fascinating to explore visually.
Here I have tried to see how a landscape might be formed from these visuals. As a method to draw out pattern and repetition. I think this particular test makes me begin to think of quite a few ideas:
Firstly, the way in which the machine learning data is conveyed to us vastly shifts our perspective on it. The initial section where the data is smoothed out to see averages, when we don’t regard this data as faces at all but a landscape, the patterns which are visible go less noticed, Once watching for a second time, we begin to see the repetition more so, than before it was revealed to us.
Later on in the animation, when the faces are rapidly played one after another, the consistencies are again noticed. The eyes pierce across all frames, hollow and evidently with glasses. The fact that a computer continues to notice these, feels as though it references something of the computer beginning to have a soul. The notion of sentient AI is incredibly controversial, and yet it starts to feel more of a reality as it can be used to form realistic terrains and abstract human portraits at the click of a couple of buttons.
But perhaps this is just the framing which I am placing onto it. The way this data is conveyed to the viewers completely manipulates what could be argued as meaningless intent by the machine. However I feel that thinking again about the UCL Media Anthropology Lab conference brief, about evolving ways of learning within indigenous space, the questions poised here are highly relevant.

Reading through this review article from Holbraad and Pedersen’s 2017 text, which the conference seeks to build upon, and the ideas of otherness, and seeking new knowledge which the conference aims to focus on, I am writing a draft of an extract which could be included with a series of visual works like the ones I have created above:
With new positioning on both the meaning we give to ontology, and the ideas which can be regarded as indigenous, creating exploratory designed works exploring these notions in alternate spaces which may currently be associated with alterity is extremely relevant. The way Machine Learning is beginning to alter existing norms in digital realms and further spaces which it is beginning to permeate will shift cultural norms as it reflects our own human traits back onto us. This series of dynamic digital metaphors aims to visualise how machines may begin to reflect all aspects of the human condition, and how concepts of materialism and narcissism may be perceived and translated into digital realms by them. Examining how they translate our data, and in what forms this could manifest into volumetric space. Due to the nature of Machine Learning itself, these metaphors remain abstracted, and therefore in many ways benefit from designed output, rather than something too heavily based in data. This allows for the viewer to question more of the machines potential future place in anthropology, and how this will further shift definitions of ontology.
Here I have begun to try and make this machine learning data set more spatial, following on from the previous animation I made, I wanted to look more at this one moment where the Machine data models became 3D in a water like sense. Here I have made 2 separate animations which explore the geometry of these dimensionally expanded data sets. The first is the raw data, which is very rough and in some ways hard to see any patterns form, and the second, is a smoothed and averaged set which was done by averaging the image input in a blurred form. I think this second version not only evokes more spatial interest, but makes it more possible to see patterns within the space if you were to explore it.
After figuring out how to export the above visual data, by baking the displacement into the model itself, I was able to make the data attach to the mesh itself rather than just be a modifier upon it. Here I have put this model into a game engine, and it forms a rather uncanny and quite realistic desert scene when textured in an alternate way.
I want to explore the process from start to finish of generating this environment and how the data converts from images input, into a completely different looking landscape. Here is a rough cut of how this flow through could look visually. I want to smooth some of the visuals and transitions, as well as giving the work more of a title, as well as adding narration and aligning the extract more clearly with the video.
